The Six Levels of LLM Applications

Amidst the prevalent myths and misconceptions about what LLMs can and cannot do, it's crucial to have a clear perspective on their practical applications. This is an attempt to provide you with a mental model, detailing various levels at which LLMs operate, which can help you determine where they best fit within your own projects. We will begin by exploring the distinct levels of LLM applications and gain insights into the current uses of LLMs and how you can adapt them for your specific needs. To visualize our discussion, here is the picture of a pyramid sliced horizontally into six levels. Like any pyramid, the peak represents our ultimate, aspirational goal, while the base signifies the most accessible starting point.
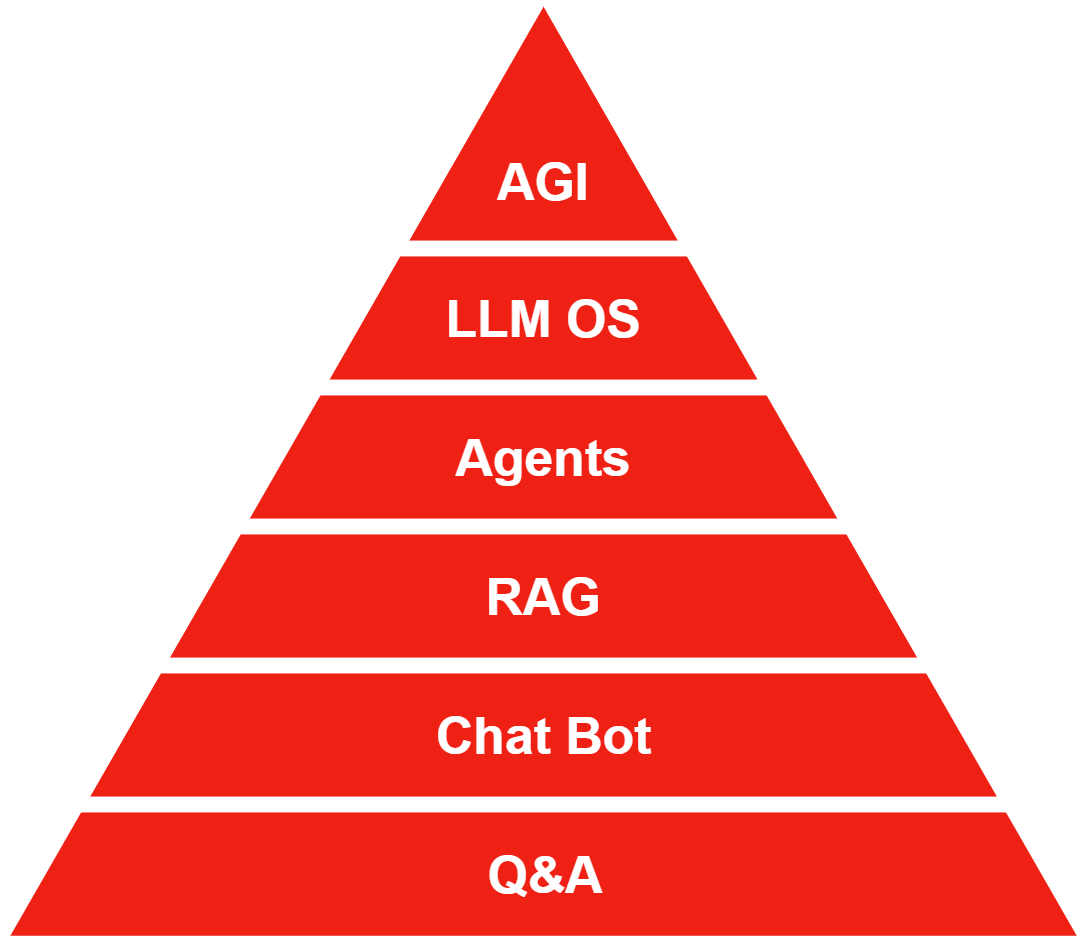
The pyramid visually represents the hierarchical structure of Large Language Model (LLM) applications, illustrating the progression from basic to advanced functionalities. At the base of the pyramid are the simplest applications such as Text Completion and Q&A, which rely primarily on prompt-based interactions and short-term memory. As we ascend the pyramid, each level introduces additional capabilities. At the top of the pyramid, LLM OS and AGI represent the zenith of LLM capabilities to operate with a level of complexity and autonomy similar to human cognitive processes. This pyramid serves as a conceptual map for understanding the gradual increase in complexity and potential of LLM technologies, from simple text-based tasks to comprehensive, intelligent systems capable of general-purpose reasoning and decision-making.
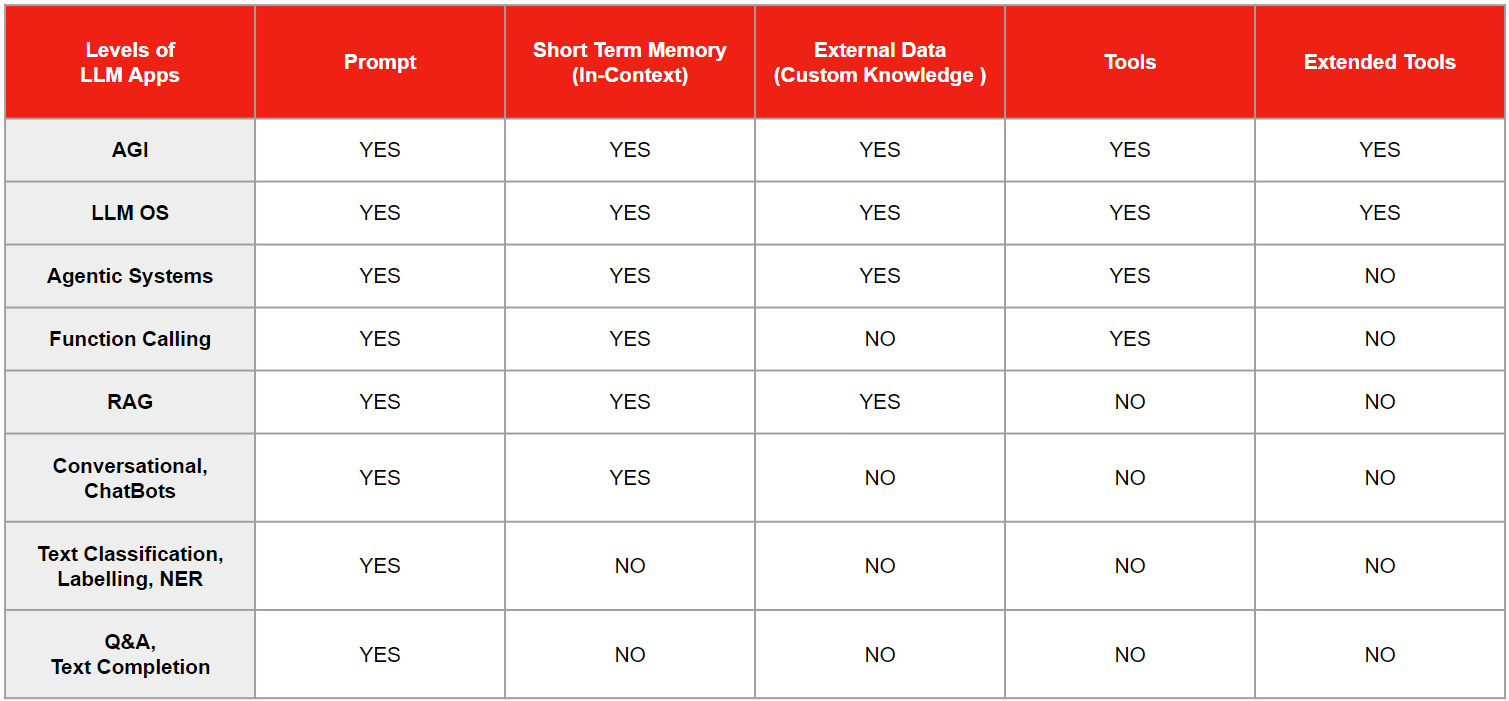
The table above offers a structured overview of the progression in capabilities across different levels of Large Language Model (LLM) applications, ranging from basic text completion to the conceptual pinnacle of Artificial General Intelligence (AGI). Each row represents a distinct level of LLM functionality, detailing the presence of specific features. This table visually encapsulates the incremental advancement and layering of technological complexities within LLM systems, illustrating a clear pathway from basic to advanced AI functionalities.
Q&A: The Foundation of LLM Applications
The foundational level of Large Language Models (LLMs) is the Question and Answer (Q&A) system. This is a straightforward application where an LLM functions as a sophisticated question-answering engine. Here's how it works: a user submits a prompt(query), and the LLM processes this prompt to generate a relevant answer. Large Language Models are essentially advanced next-word prediction systems that have been fine-tuned through a process called instructional fine-tuning. This allows them to interpret human instructions and provide accurate responses. For instance, if you ask, "What is the capital of the UK?" the LLM processes the question and responds with "London". This Q&A capability is not just the most basic application of LLMs but also the earliest. Back then, developers initially focused on creating simple Q&A bots. These bots are primitive and can be used for answering general knowledge questions. This simple use case forms the base of our LLM application pyramid.
Expanding LLM Capabilities
As we progress beyond the basic Q&A application, we enter the level of developing conversational chatbots. This advancement involves understanding and implementing what can be referred to as the "five dimensions" of LLM applications. These dimensions, which function as enhancements to the traditional LLM framework, allow for more complex and interactive systems.
- Prompt: The prompt is the initial input given to an LLM, such as asking, "What is the capital of UK?" The LLM processes this prompt and returns the answer, "London."
- Short-term Memory (In-Context Learning): This involves the LLM retaining information within the current conversation or session—akin to a computer's RAM. For example, if previous questions in a session include queries about capitals, the LLM uses this context to enhance its responses to similar future questions within that session.
- External Data (Long-term Memory): Here, the LLM accesses external databases or knowledge bases, like Vector Stores, to incorporate broader and more detailed information that is not stored within its immediate context.
- Tools: This dimension allows LLMs to utilize additional functionalities like calculators or access to the internet, enabling them to perform more complex tasks and provide more comprehensive responses.
- Extended Tools: This represents a further expansion where LLMs interact with even more sophisticated tools or datasets, significantly broadening their capabilities and the complexity of tasks they can handle.
Understanding these dimensions helps to appreciate how LLMs can be developed from simple question-answering engines into fully interactive systems that simulate more nuanced human-like conversations and reasoning abilities. Each of these dimensions adds a layer of complexity and utility, transforming how LLMs function and are applied across different scenarios.
ChatBot: Enhancing Interaction with Short-term Memory
The progression from a simple Q&A bot to a conversational chatbot represents a significant step up in the pyramid of LLM applications. The transformation involves the integration of what we call "short-term memory" or "in-context learning." A basic Q&A bot operates on straightforward prompts: you ask, "What is the capital of UK?" and it replies, "London." However, to evolve this into a chatbot, we introduce a crucial enhancement—short-term memory. This allows the chatbot to retain a history of the conversation, adding depth to the interaction. For instance, after identifying London as the capital, you might follow up with, "What do people eat there?" With the context of the previous question stored, the chatbot understands that "there" refers to London and responds accordingly. This capability is facilitated through a process known as in-context learning, where the LLM retains information from the ongoing dialogue to provide more relevant and connected responses.
Applications and Limitations of Chatbots
Chatbots are incredibly versatile, finding utility across numerous sectors. They are prevalent in customer support, where they provide immediate responses to user inquiries, and on websites, offering guidance or answering FAQs. The educational sector also leverages chatbots; platforms like Duolingo and few other language learning applications use them to enhance interactive learning experiences.
Despite their utility, chatbots have limitations, primarily due to their reliance on short-term memory alone. For more complex interactions, there is often a need for access to long-term or external memory. This would allow a chatbot not only to recall previous interactions within a session but also to pull in detailed data from external sources, thereby enriching the conversation and making the responses more informative and contextually appropriate. This need for deeper, more detailed knowledge reflects why merely having a chatbot isn't sufficient for all applications. As we ascend the pyramid, the integration of additional dimensions—like long-term memory—becomes critical to expanding the capabilities and effectiveness of LLMs in more sophisticated environments.
Utilizing LLMs for Classical NLP Tasks
As we delve deeper into the capabilities of Large Language Models (LLMs), it's crucial to recognize their versatility. LLMs hold significant potential for classical NLP (Natural Language Processing) tasks, often leveraging their inherent strengths in context learning and short-term memory to achieve impressive results. Classical NLP tasks encompass a variety of operations such as text classification, entity recognition (NER), and text summarization. Traditionally, these tasks would require the development of specialized models based on frameworks like BERT or machine learning techniques such as XGBoost. However, LLMs present an efficient alternative that can often outperform these traditional methods in certain contexts.
Consider a text classification scenario where the sentence "The opening ceremony of the 2024 Paris Olympics has been horrendous in every way" needs to be categorized as positive or negative sentiment. Similarly, a review stating "The performance was horrendous but the actress was exceptional" might be classified based on the focus of the review (e.g., performance, actress). LLMs can handle these tasks effectively using few-shot or zero-shot learning approaches, where they classify texts based on minimal examples or even without direct examples of each category.
Advantages of LLMs in NLP
- Flexibility: LLMs can adapt to various NLP tasks without the need for extensive retraining or fine-tuning.
- Efficiency: They reduce the necessity to build custom models for each specific task, saving resources and development time.
- Contextual Understanding: With their advanced capabilities in handling context, LLMs can provide nuanced insights and classifications based on the textual data provided.
While LLMs offer a robust solution for many classical NLP tasks, it's important to weigh the cost and efficiency of using such models compared to building custom solutions. For organizations or individuals without the capacity to develop complex models, LLMs serve as a powerful tool that can be quickly implemented to handle a range of NLP challenges.
RAG Retrieval-Augmented Generation
In the LLM application pyramid, moving up from the chatbot level, we encounter the need for a more sophisticated approach called Retrieval-Augmented Generation (RAG). This technique addresses the limitations of relying solely on a model's internal data or short-term memory, particularly in complex enterprise contexts.
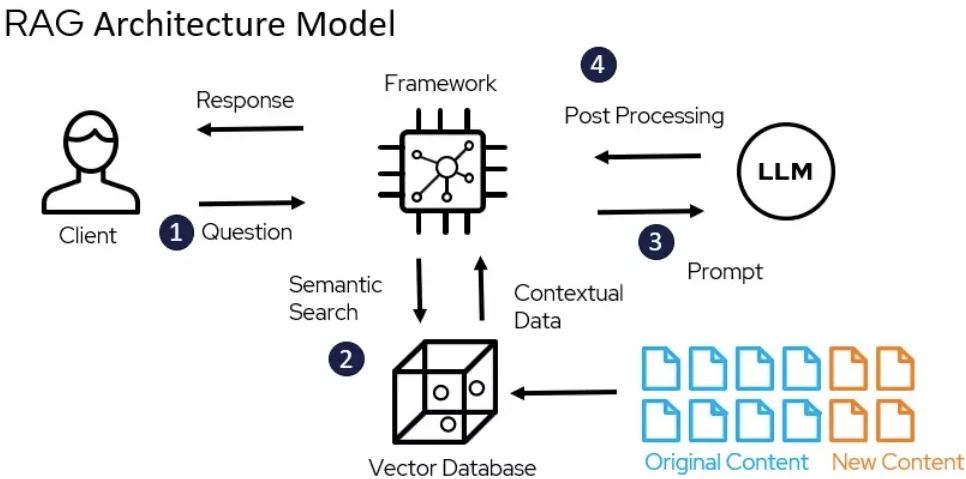
Consider a hypothetical scenario involving a large company, like Red Hat. If you ask an LLM, "Who is the CEO of Red Hat?", it easily retrieves "Matt Hicks" from the internet. However, more intricate queries such as, "Who manages the team handling Instruct Lab project?" pose a challenge. These require not just generic internet knowledge but specific, tailored information that traditional LLMs or chatbots might not access accurately.
RAG addresses these challenges by incorporating a variety of external data sources, such as structured databases, unstructured documents, and direct API calls, into the LLM’s processing framework. This integration enables the LLM to access a wide array of information that extends beyond the immediate conversation and its pre-existing datasets.
Key Components of RAG:
- Data Sources: These can vary widely depending on the organizational needs—from structured databases like RDBMS, to unstructured formats like PDFs and TEXT files, to programmatic access through APIs for systems like Salesforce.
- Index Creation: Similar to how Google indexes the web to efficiently retrieve information, RAG systems index available data. This index acts as a comprehensive yet selective filter that assists in pinpointing relevant information for any given query.
- Query and Retrieval: When a query is made, such as asking for the manager of the Instruct Lab Project team, the system searches the index to find the most relevant data before it's sent to the LLM. This ensures that the LLM operates with the most accurate and contextually appropriate information.
Advantages of RAG
This method significantly enhances an LLM's ability to provide accurate and relevant answers by ensuring it does not rely on potentially incorrect or outdated internal data. By connecting directly to real-time, external data sources, RAG expands an LLM's utility in professional settings where precision and up-to-date information are crucial.
You might wonder why this indexed, external data approach is preferred over simply expanding the LLM's memory. The answer lies in the limitations of what's known as the "context window" of LLMs. Context window is basically how much information an LLM can consider at one time without losing coherence or accuracy. As discussions or queries become complex, maintaining all relevant data within an LLM's immediate memory becomes impractical due to the context window limitations.
Introduction to Agentic Systems
As we ascend further up the pyramid of LLM applications, we enter the level of agentic systems—a domain that has captured widespread interest across major tech players like Google, Microsoft, and previously, OpenAI. This level reflects significant advancements in AI capabilities, highlighted by two major trends: multimodality and the emergence of agent-based systems.
Understanding Multimodality
Multimodality in LLM applications extends the interaction beyond traditional text-based inputs and outputs. It encompasses the ability to engage with multiple forms of media. For instance, users can now interact with AI through voice commands, receive responses in speech, initiate queries with images, and even use videos as a mode of communication. This expansion greatly enhances the user experience and opens up new possibilities for how AI systems can be utilized in everyday tasks and professional environments.
Understanding Function Calling
Before diving into the intricate world of agentic systems, it's essential to understand a pivotal concept known as "function calling," which acts as a precursor to these systems. Function calling is a method that enables LLMs to interact with external tools, although the name might be a bit misleading as it suggests direct invocation of functions, which is not precisely what happens.
In function calling, the LLM is tasked with producing structured responses suitable for interacting with external APIs or systems. This method doesn't involve the LLM directly calling functions in the traditional programming sense. Instead, it prepares the LLM to generate outputs in a format that can be used to make such calls externally—typically by another program or system handler.
Example: Cryptocurrency Conversion
Imagine you need to convert cryptocurrency values using an API. Essential inputs for this API call would typically include the source currency, target currency, date, and the amount to convert. For instance, if you ask LLM, "What is the conversion rate from Bitcoin to USDT today?", the LLM needs to accurately structure the response with all these necessary parameters. This task involves recognizing 'today' as the current date, understanding cryptocurrency symbols (like BTC for Bitcoin and USDT for Tether), and formatting the response correctly, typically in a JSON format.
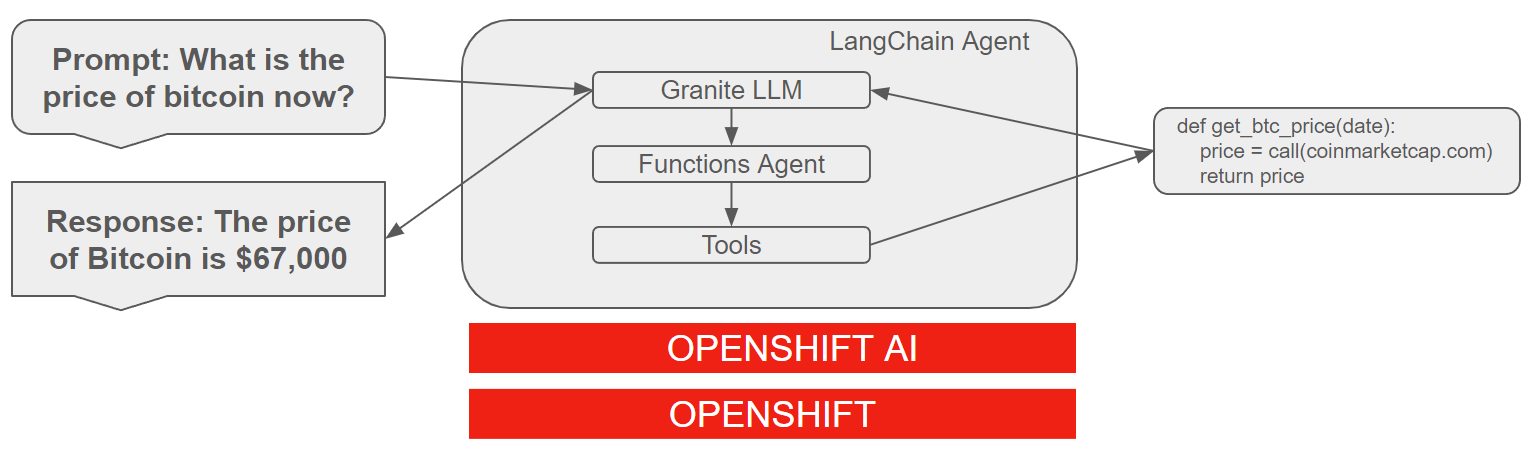
Challenges in Function Calling
- Temporal Awareness: LLMs often operate with a "frozen" knowledge base, reflecting data only up until their last training cut-off. They don't inherently know 'today's' date or current events, which can be critical in tasks like currency conversion that depend on real-time data.
- Structured Output: To effectively integrate with external systems, the output from an LLM must be highly structured. This is typically handled by formatting responses in JSON (or XML in some cases), which can then be used to make an API call.
- Precision in Responses: The response must be precise and consistent, using the exact terminology and data formats expected by the external systems. Variability in terms like "USDT," "Tether," or "USDT Stablecoin" can lead to errors unless the LLM is guided to standardize its output.
Function calling allows LLMs to extend their utility beyond generating text-based responses. By formatting their outputs correctly, LLMs can effectively interface with other digital tools, enabling more dynamic and functional interactions. This capability is crucial for developing full-fledged agentic systems, where such structured outputs are used to orchestrate a series of function calls, culminating in the execution of complex tasks.
Understanding function calling is important for grasping how agentic systems operate. Agents in such systems essentially perform a series of function calls, but with a level of autonomy and coordination that mimics human-like agency. These agents can dynamically interpret tasks, execute functions across different tools, and manage interactions that involve complex sequences of operations. Function calling is a critical component that bridges simpler LLM applications to more advanced, interactive agentic systems.
Understanding Agentic Systems
Agentic systems are built upon the foundation of function calling but extend much further by incorporating specific tools and objectives to create agents with distinct roles and purposes. An agent in this context is not merely an application responding to inputs but is an entity programmed to initiate actions and achieve goals. Agentic systems are composed of multiple agents that can be summoned to perform specific tasks. Unlike earlier models where interactions were generally static and limited to predefined functions, agentic systems are dynamic, capable of operating semi-autonomously to accomplish a variety of actions based on user commands. Agents are designed to go beyond static interactions (like text or image responses) to actively engaging in actions. This could be anything from booking tickets and creating notes to publishing blog posts. The defining feature of an agent is its ability to transform a text command into a tangible outcome, effectively bridging the gap between digital operations and real-world actions.
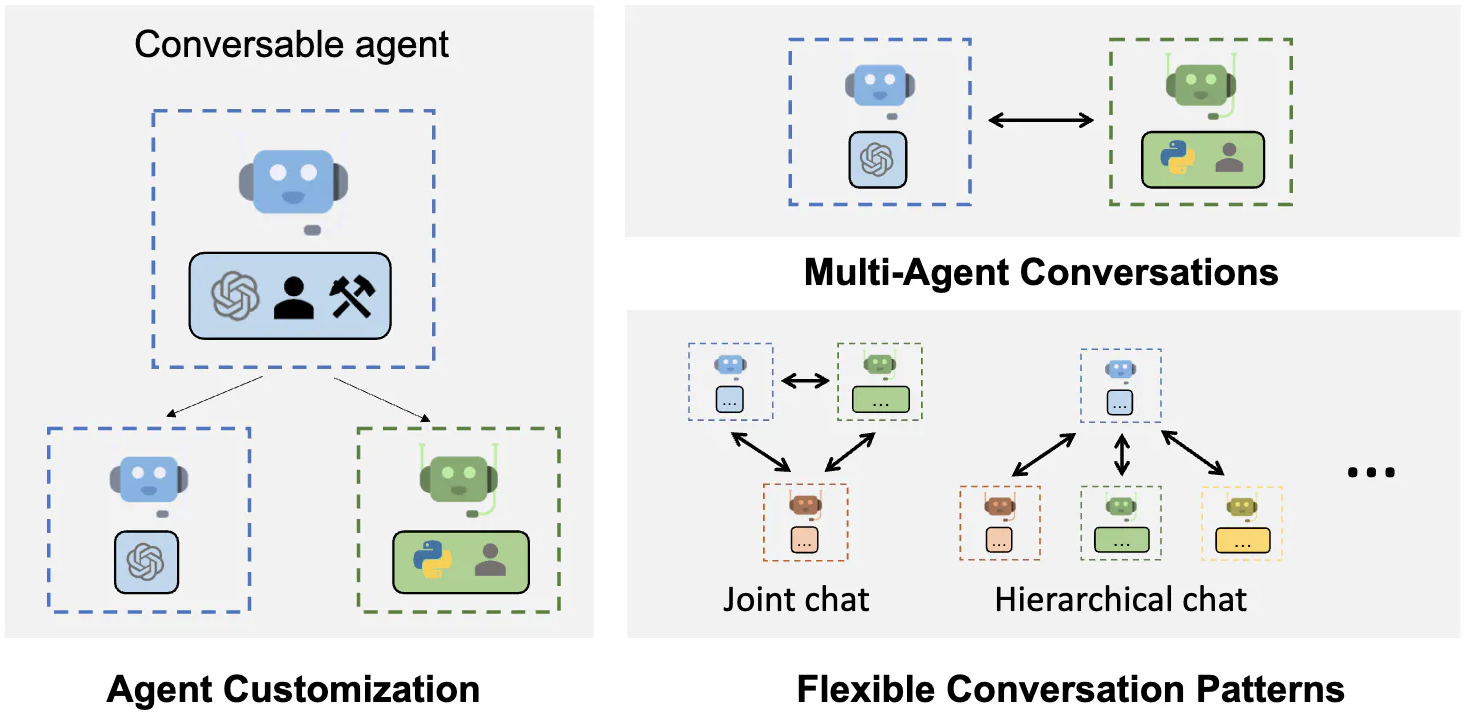
Key Features of Agentic Systems:
- Task-oriented Capabilities: Each agent within the system is designed to handle particular tasks, ranging from simple data retrieval to more complex problem-solving scenarios.
- Inter-agent Collaboration: In multi-agent setups, agents can work together, sharing information and resources to complete tasks more efficiently and effectively.
- User-directed Operations: Users can direct specific agents to perform tasks, providing a level of interaction and control that mimics engaging with human assistants.
These advancements represent a paradigm shift in how we envision and interact with AI. Agentic systems not only offer more personalized and engaging experiences but also pave the way for more sophisticated applications where AI can assist in a broader range of activities, mirroring the complexity and versatility of human agents. This stage in the LLM application pyramid demonstrates the potential of AI to not just respond to queries but to actively participate and assist in achieving user-defined goals.
Modern agentic frameworks such as LangChain, LangGraph, CrewAI, Flowise or Microsoft AutoGen showcase the evolution of agent capabilities. These systems typically require users to define a role and a goal for each agent, choosing an appropriate LLM to serve as the backend engine. These agents can operate individually or in teams, forming a multi-agent setup that can handle complex, multifaceted tasks. The concept of agentic systems is not just a theoretical exploration but is rapidly becoming a practical solution adopted by major technology firms like Google and OpenAI. Each iteration and implementation of these agents are steps toward more seamless integration of AI into daily tasks and professional operations, pushing the boundaries of what AI can achieve.
LLM OS: The Future of LLM Applications
As we near the pinnacle of our exploration into the layers of LLM applications, we encounter a concept that could redefine how we interact with technology: the LLM Operating System (LLM OS). Inspired by the forward-thinking ideas of Andrej Karpathy, LLM OS represents the aspirational goal of integrating LLMs as the core of an advanced computational framework. Andrej Karpathy is a computer scientist who served as the director of artificial intelligence and Autopilot Vision at Tesla. He co-founded and formerly worked at OpenAI, where he specialized in deep learning and computer vision.
The Concept of LLM OS
LLM OS envisions placing an LLM at the heart of an operating system, much like the CPU in traditional computers. This system isn't just a tool or a component; it's the central processing unit around which all other functions revolve, from basic computations to complex interactions with the digital and physical world.
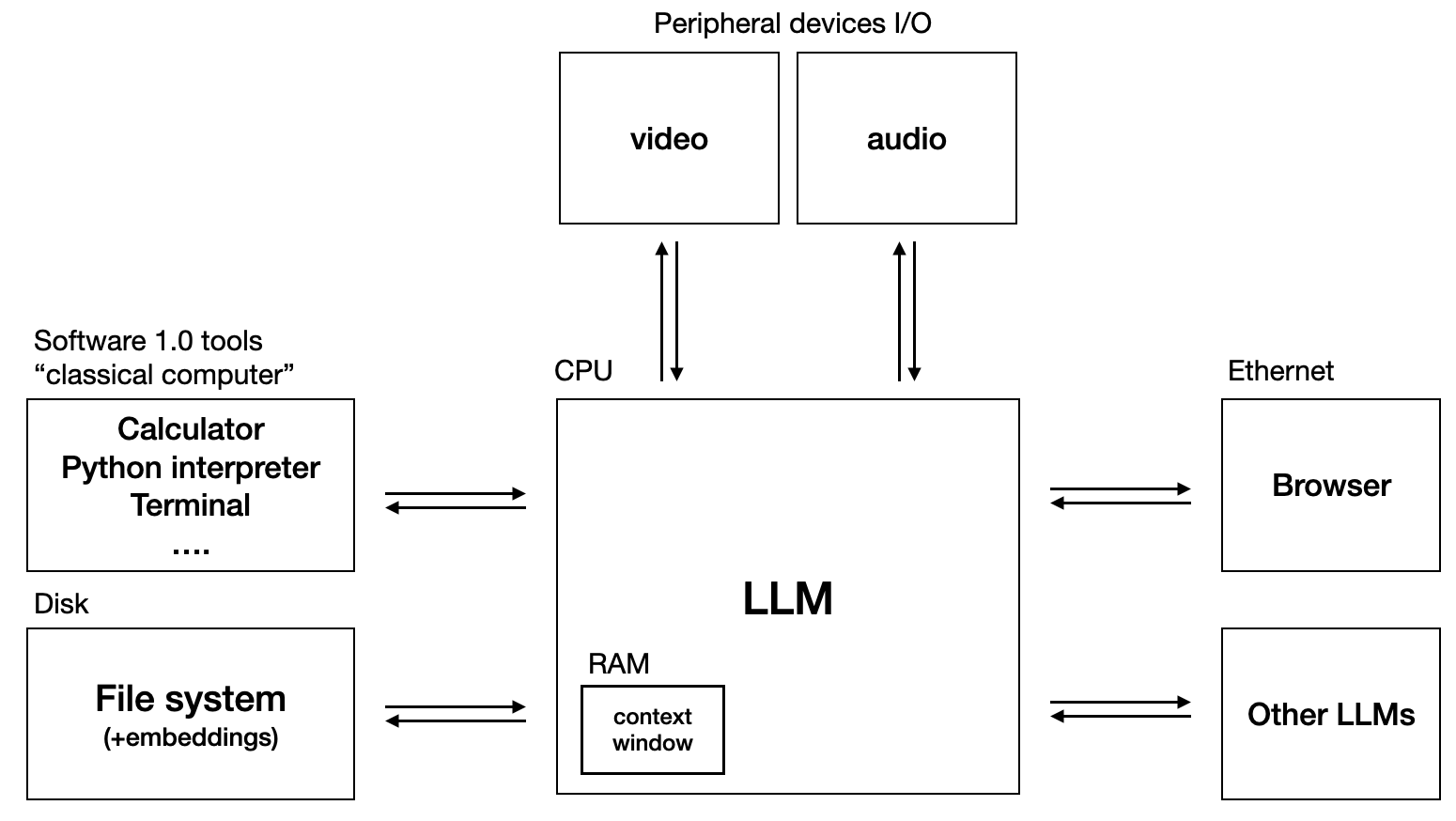
Components of LLM OS
- RAM and Short-term Memory: This parallels the concept of RAM in computers, where the LLM utilizes a context window to manage immediate data processing tasks, providing the capacity for quick recall and response.
- Long-term Memory and RAG: Similar to a computer’s hard drive, LLM OS would use techniques like Retrieval-Augmented Generation to access a vast, detailed archive of information, allowing for deeper and more accurate data retrieval.
- Agentic Systems and Tools: At this layer, LLMs employ various tools to perform specific tasks, functioning similarly to applications on a traditional OS but in a more dynamic and adaptive manner.
- Connectivity: Integration with the internet and other LLMs facilitates a multi-agent setup, expanding the system’s capabilities to operate both independently and in coordination with other systems.
- Peripheral Interfaces: Including audio and video processing capabilities, allowing the system to interact with the user in multiple modalities, enhancing accessibility and user experience.
The Vision of LLM OS
The overarching vision of LLM OS is to create a system where all these components work together seamlessly towards common objectives, driven by user inputs and autonomous operations. This would not only make interacting with digital systems more intuitive and effective but also extend the potential applications of LLMs across all areas of personal and professional life. Although still largely conceptual, some implementations of LLM OS exist that integrate elements of function calling, agentic systems, and multimodal multi-agent operations. These early versions are foundational, demonstrating the feasibility of such a system while also highlighting areas for further development and refinement.
LLM OS is more than just an operating system; it's a potential revolution in how we conceive of and interact with computational technology. By centralizing LLMs within the system architecture, LLM OS could dramatically enhance the efficiency, scalability, and capabilities of digital systems, making sophisticated AI interactions commonplace in everyday technology use. As this concept continues to develop, it promises to unlock new dimensions of what technology can achieve, guided by the intricate and powerful capabilities of Large Language Models.
AGI
Artificial General Intelligence (AGI) stands at the apex of the LLM application pyramid, embodying the ultimate goal of creating machines that can perform any intellectual task that a human being can. AGI is distinguished by its ability to reason, plan, solve complex problems, understand complex ideas, and learn independently. It encompasses a level of cognitive flexibility and adaptability that goes far beyond the specialized functionalities of current AI systems, including those described in LLM OS or agentic systems. AGI aims to achieve a form of machine intelligence that is not only reactive to its environment but also proactive, capable of abstract thinking, and possessing common sense on par with human beings. This level of AI could potentially transform every aspect of society, from revolutionizing industries to reshaping our understanding of intelligence itself. While still largely theoretical and subject to considerable ethical, technical, and philosophical debate, AGI represents the horizon of AI research and development.
Closing Thoughts
As we wrap up our exploration of LLM applications from basic Q&A systems to the advanced LLM Operating System, we find ourselves at the cusp of a major evolution in artificial intelligence. While AGI is still largely theoretical, linked to complex discussions about consciousness and reasoning, the development of LLM OS offers a more immediate and realistic advancement. LLM OS blurs the lines between human and machine by processing and interacting with information in sophisticated ways. By continuing to refine and integrate these systems, we advance the role of AI in our lives, envisioning a future where AI not only supports but significantly enhances our interactions with the world.